Agenta
Agenta is the open-source LLMOps platform that streamlines AI app development with centralized collaboration and.
Visit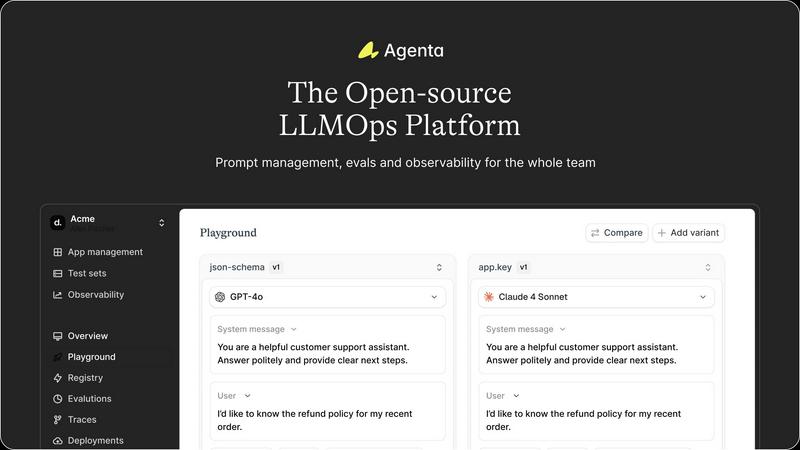
About Agenta
Agenta is the open-source LLMOps platform specifically designed to transform the way AI teams develop and deploy large language models (LLMs). By addressing the chaos and unpredictability that often accompany LLM development, Agenta provides a structured environment that promotes collaboration among developers, product managers, and domain experts. Its primary focus is on streamlining the LLM lifecycle, enabling teams to swiftly iterate on prompts, validate changes, and debug issues effectively. Agenta centralizes prompt management, automated evaluations, and production observability into a unified workflow, significantly reducing time-to-production while enhancing the reliability and performance of AI applications. Model-agnostic and framework-friendly, Agenta integrates seamlessly into existing tech stacks, empowering teams to build robust AI products without the risk of vendor lock-in. The platform serves as the essential infrastructure for teams eager to accelerate their LLM development journey, ensuring that experimentation leads to reliable, shipped applications.
Features of Agenta
Centralized Prompt Management
Agenta centralizes all prompts, evaluations, and traces on one platform. This eliminates the chaos of scattered workflows, allowing teams to focus on prompt optimization and collaboration without losing valuable insights.
Automated Evaluation Process
Agenta introduces an automated evaluation process that replaces guesswork with evidence-based decision-making. Teams can systematically run experiments, track results, and validate every change, ensuring reliable performance improvements.
Unified Playground
The unified playground allows teams to compare prompts and models side-by-side. This feature enables quick iterations and testing, ensuring that errors can be identified and corrected efficiently, leading to enhanced product quality.
Comprehensive Observability
With comprehensive observability features, Agenta allows teams to trace every request and pinpoint failure points easily. This functionality enhances debugging capabilities, enabling teams to gather user feedback and monitor system performance in real-time.
Use Cases of Agenta
Rapid Prototyping of AI Applications
Agenta facilitates rapid prototyping by allowing teams to experiment with various prompts and models simultaneously. This accelerates the development cycle, enabling faster deployment of AI features with higher confidence in their effectiveness.
Cross-Functional Collaboration
Teams can collaborate effectively through Agenta's integrated platform. Product managers, developers, and domain experts can work together seamlessly, reducing silos and enhancing communication throughout the LLM development process.
Error Resolution and Debugging
When issues arise in production, Agenta makes it easy to trace and annotate errors. Teams can turn any trace into a test with a single click, streamlining the debugging process and closing the feedback loop quickly.
Performance Monitoring and Improvement
Agenta supports continuous performance monitoring through live, online evaluations. This allows teams to detect regressions and systematically improve their LLM applications, ensuring that they meet user expectations consistently.
Frequently Asked Questions
What types of teams can benefit from Agenta?
Agenta is designed for cross-functional teams, including developers, product managers, and domain experts, who are involved in LLM development and deployment.
Is Agenta compatible with existing tech stacks?
Yes, Agenta is model-agnostic and framework-friendly, allowing seamless integration with your current tools and systems without any vendor lock-in.
How does Agenta enhance collaboration among team members?
Agenta provides a unified platform where prompts, evaluations, and traces are centralized, fostering collaboration among team members and ensuring everyone has access to the same information.
Can I use Agenta for both development and production environments?
Absolutely! Agenta is built to support the entire LLM lifecycle, from experimentation during development to robust observability and monitoring in production, ensuring reliable AI application performance.
Explore more in this category:
Similar to Agenta
MCPize is a marketplace where developers can discover, install, and manage 1,000+ premium MCP servers while publishers keep 80% of revenue.
The Tool Empire offers 82 powerful, free, browser-based tools for developers, designers, writers, and students without any sign-ups or server delays.
Agyn is an open-source AI agent management platform that ensures secure, budget-conscious deployment across your teams and environments.
act101 gives coding agents 163 grammars and 183 AST operations to instantly refactor and port code across languages.
BoltShot is the fastest API for capturing perfect screenshots instantly from any URL with no browser ops required.