Google Cloud Speech-to-Text
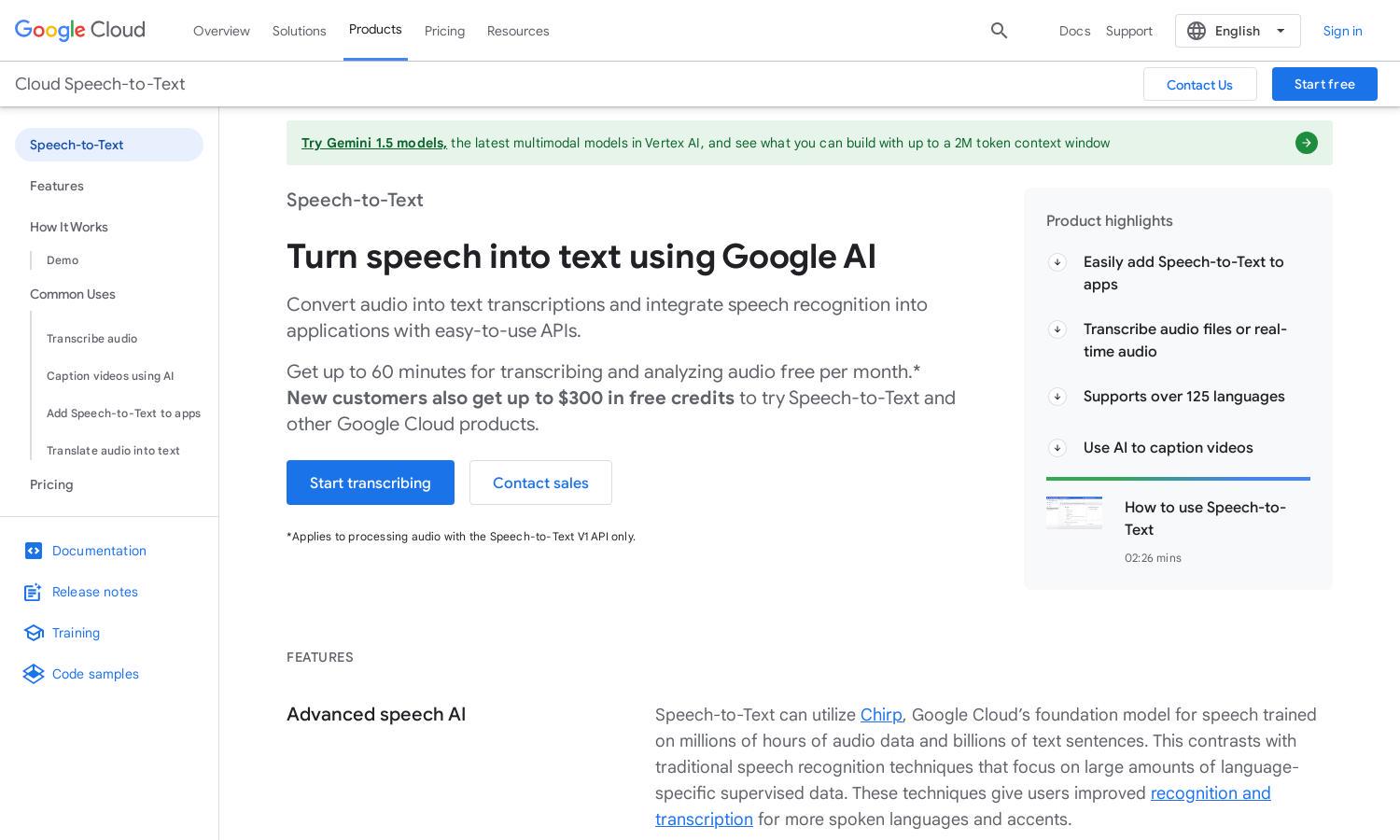
About Google Cloud Speech-to-Text
Google Cloud Speech-to-Text empowers users to convert speech into text with high accuracy across more than 125 languages. Its innovative Chirp AI model excels in understanding diverse accents and nuances, providing tailored transcription services for various applications, making it ideal for businesses and developers seeking reliable audio transcription solutions.
Google Cloud Speech-to-Text offers flexible pricing plans. A free tier allows new users to transcribe audio at no cost for the first 60 minutes monthly. V1 is priced at $0.024 per minute, while the more advanced V2 API is $0.016 per minute, featuring enhanced capabilities, making it affordable for all.
The user interface of Google Cloud Speech-to-Text prioritizes simplicity and accessibility. With a clean layout and intuitive navigation, users can easily access features for transcription, customization, and monitoring. Its streamlined design helps users maximize productivity and experience seamless audio-to-text conversion, enhancing overall satisfaction with the platform.
How Google Cloud Speech-to-Text works
To start using Google Cloud Speech-to-Text, users simply sign up and gain access to the API. After setting up their project, they can easily upload audio files or stream live audio for transcription. The service processes the audio in real time or batch mode, delivering accurate text results while supporting customization for specialized needs, ensuring an efficient user experience.
Key Features for Google Cloud Speech-to-Text
Real-Time Speech Recognition
Real-time speech recognition is a key feature of Google Cloud Speech-to-Text, enabling users to receive immediate transcription results as they speak or stream audio. This timely capability enhances user interaction and provides rapid, accurate text outputs for applications like live captioning and audio analysis, ensuring seamless communication.
Advanced Customization Options
Google Cloud Speech-to-Text offers advanced customization options, allowing users to tailor transcription models to recognize domain-specific terminology and enhance accuracy. This feature is crucial for industries with specialized vocabulary, providing businesses with reliable audio transcription that meets their unique needs and improves overall operational efficiency.
Multichannel Recognition
Multichannel recognition is an impressive feature of Google Cloud Speech-to-Text, allowing the platform to process and differentiate between multiple audio channels seamlessly. This function is particularly beneficial for transcribing multi-speaker environments, such as video conferences, ensuring clear and organized transcripts that accurately reflect each speaker's contributions.
You may also like: