Friendli Engine
About Friendli Engine
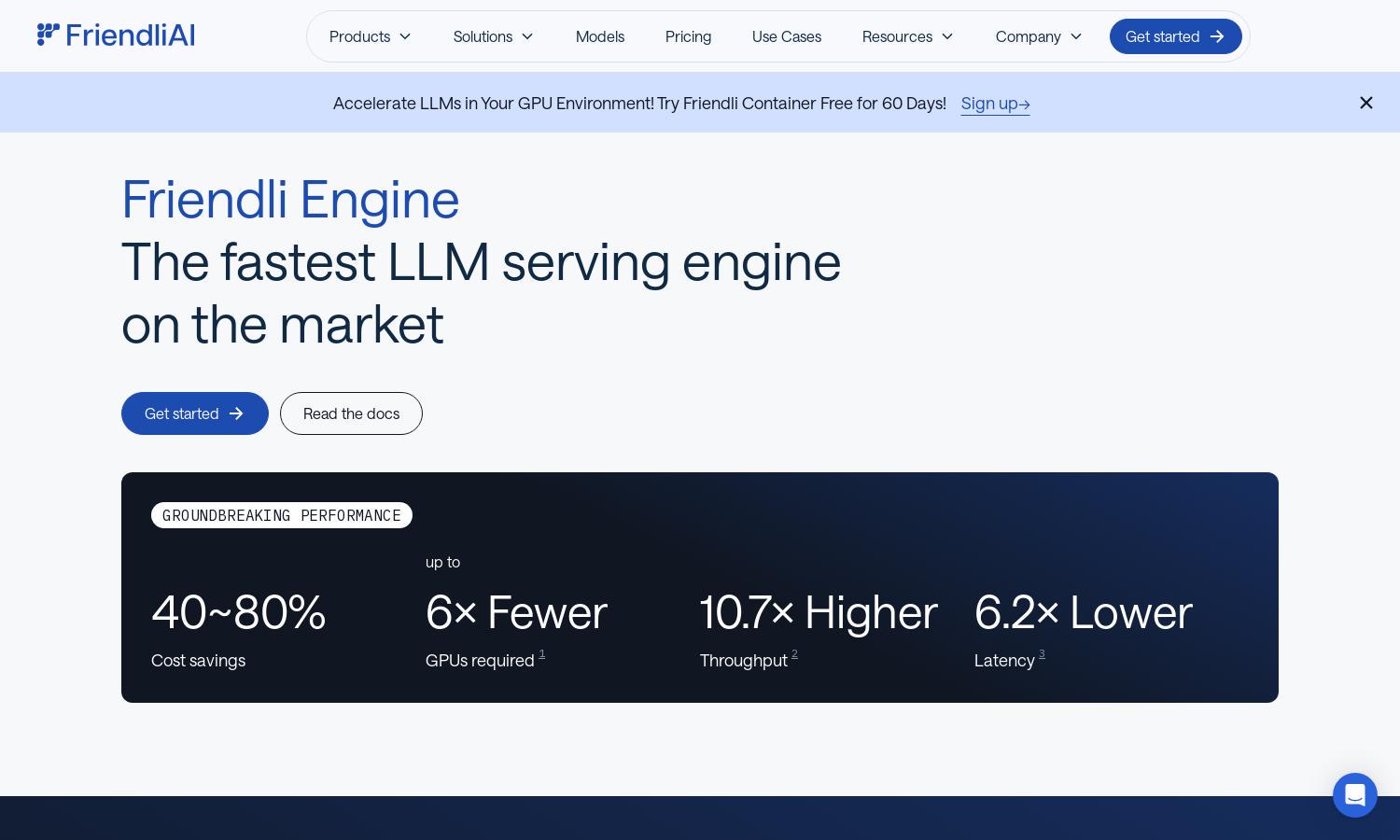
Friendli Engine is a revolutionary platform designed to enhance LLM inference speed and cost-effectiveness. It targets AI developers and businesses aiming for optimal performance with minimal resources. Its innovative features, like iteration batching and speculative decoding, ensure significant cost savings while maintaining high-quality outputs.
Friendli Engine offers flexible pricing plans tailored to various users. Subscriptions include options for individuals and enterprises, with discounts available for long-term commitments. Each tier unlocks advanced features, helping users maximize efficiency and performance in LLM inference.
Friendli Engine boasts a user-friendly interface, designed for seamless navigation and efficiency. The intuitive layout facilitates effortless access to key functionalities, ensuring users can optimize their generative AI models without obstacles. Unique features enhance the user experience, making AI deployment straightforward and effective.
How Friendli Engine works
Users begin by selecting a deployment option on Friendli Engine, enabling them to run generative AI models easily. Onboarding involves setting up account preferences and accessing model lists. The platform’s layout guides users to features like iteration batching, enabling efficient LLM serving. With tools designed for optimization, navigating through model deployment becomes intuitive and efficient, ensuring all users can achieve the best performance possible.
Key Features for Friendli Engine
Iteration Batching Technology
Iteration batching is a groundbreaking feature of Friendli Engine that maximizes LLM inference throughput. By efficiently managing concurrent requests, it achieves significantly faster response times compared to traditional batching methods, providing users with exceptional performance while reducing operational costs.
Multi-LoRA Support
Friendli Engine's multi-LoRA support allows users to utilize multiple model adaptations on a single GPU. This functionality enhances customization capabilities, making it easier and more efficient for developers to tailor their models according to specific needs without incurring high resource costs.
Friendli TCache
The Friendli TCache feature intelligently stores frequently used computation results to reduce GPU workload. This unique caching mechanism allows for significantly faster Time to First Token (TTFT), optimizing performance and improving overall efficiency for users running generative AI models on the platform.








